
10 months into 2021 we’ve had 10 minutes of downtime of the core platform we manage at work (Bench). This works out at 99.9977% uptime (or 4 nines of uptime).
I’m really proud of this. Although I’m a bit disappointed that that we didn’t get as far as 5 nines of uptime (99.999%) (which we would have achieved if we’d had just 3 minutes less of downtime).
What this means
This means that our platform was available 24 hours a day, 7 days a week for 10 months of the year (except for 10 minutes). We were able to make sure that nothing broke for almost 44,000 minutes (except for the 10 minutes where we didn’t).
This is pretty hard to do as it meant that every single part of the infrastructure we manage and all the links in between didn’t fail.
What this looks like
In Pingdom, this looks like this:

Note that Pingdom doesn’t show more than 4 nines of uptime.
And a partial log of downtime for the past 10 months.
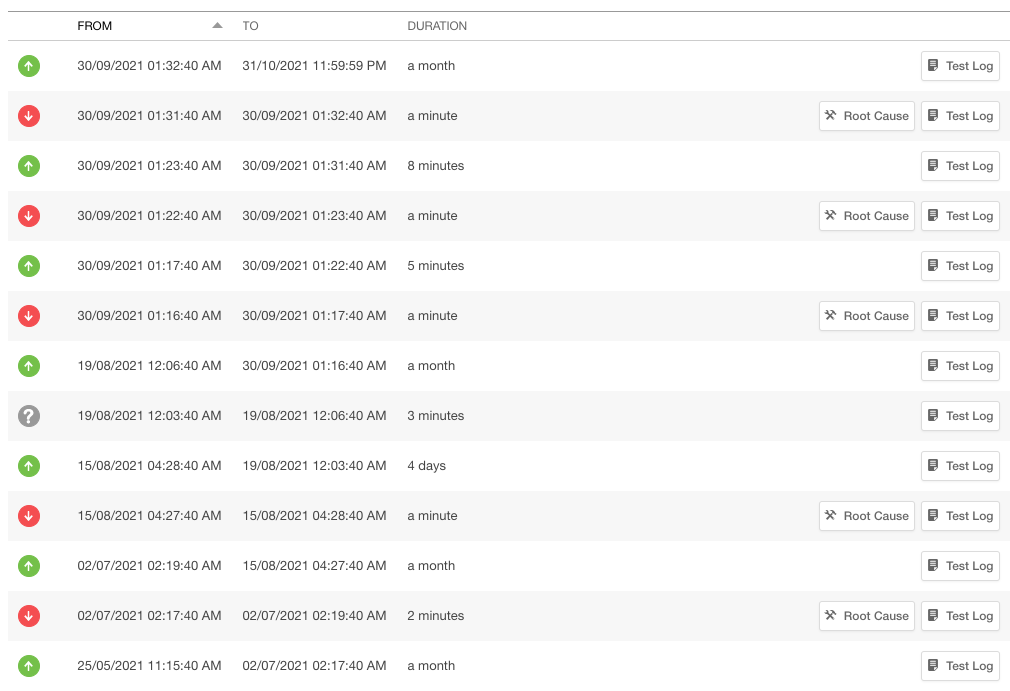
One thing you’ll notice is that many of the outages were pretty short. They’re also typically early in the morning for our timezone. When we did some digging into this, we couldn’t find any issues that matched the downtime. We speculate that these might be network connectivity issues, ie there are no problems with our platform but the tools checking the platform weren’t able to connect.
Why Uptime is a terrible measure
It’s actually quite easy to achieve very high uptime, at least for some websites. All you need to do a find some simple hosting for static files (eg AWS S3), then put a CDN in front of it (eg Cloudflare or Cloudfront). Then your uptime basically matches the uptime of your CDN.
Given that uptime is the core business of a CDN, the uptime tends to be incredibly high. Cloudflare’s enterprise agreement says:
The Service will serve Customer Content globally 100% of the time.
https://www.cloudflare.com/en-gb/enterprise_support_sla/
So for a simple website, you should be approaching 100% uptime.
Uptime also doesn’t measure whether your website actually works. The uptime measure could tell you everything is fine, even if people can’t log into your platform. It’s a measure about whether your website is there, not whether it works.
Why Uptime is a good measure
Given the limitations with uptime, why would you measure this? Well, it turns out that there is a bunch of useful things that an uptime measure tells you.
First off, assuming that the website is doing something more than just serving up static files, then this can be a useful measure. if your website does some work in order to respond to a basic check then it becomes a measure if whether your server or servers are available and working. Or at least working enough to respond to a basic request.
This means that it’s a measure of whether your servers are working 24/7. It doesn’t cover everything, but it does give you a basic indication of health. In our case at Bench, every request is coming back from our servers.
It also measures whether you can deploy new versions of software without taking your platform offline. I’ve worked at some companies where a deployment to production meant hours of downtime for each deployment.
This is also a basic measure of the quality of your infrastructure. What is the uptime of your underlying providers?
Finally, it’s a basic measure of code quality. Does your code work enough to continue to respond after each deployment? Does it scale so that it still responds under high load?
How we achieved this
This didn’t happen overnight, it was the result of quite a bit of work across quite a few different areas. Each of these is worthy of a blog post by itself, but this is a quick introduction.
Infrastructure
The infrastructure itself needed to be resilient and gracefully handle any failures. This meant multiple servers on AWS, with a load balancer routing traffic to them. The infrastructure also automatically scales up to handle any increased load so that we can continue provide a stable platform.
The other main layers of the platform (DNS – Cloudflare, DB – MongoDb on Atlas) also needed to be stable enough to provide solid uptime.
Deployments
Over that 10 month period, we deployed the platform into production 57 times, through either planned deployments or a hotfix. Suppose we had 5 minutes of downtime for each deployment, that would mean 285 minutes downtime over the 10 months. Even a more modest 1 minute of downtime would mean 57 minutes of downtime. So clearly you need a really solid deployment process to avoid downtime.
In our case, we implemented a partial blue/green deployment, where we:
- deploy new code to new servers
- add new servers to the pool
- wait for them to warm up and become healthy
- remove the old servers
So far we’ve only had 3 minutes of downtime caused by a deployment (the deployment process had a minor glitch).
Quality
The hardest part of this is to ensure that software you’re delivering into production actually works. You can have amazing infrastructure, with an amazing deployment process, but if the quality if the code isn’t there, it’s all for nothing. Of course you could just never deploy new versions of code, but then you’re not delivering new value for your customers.
You have to build quality into the entire process of building software.
One small bug written by any of the developers that slips through into production can take your entire platform down. We haven’t been immune from this. We had a couple of major issues in November 2020 which caused some disruptions of the platform from a couple of bugs we missed. Each time we learnt from the issue, the same way we have learnt from past failures, and in turn we’ve fed this back into the process.
We now have a combination of:
- code reviews
- automated tests and semi manual regression tests to ensure that the platform works
- continued emphasis on quality to ensure that everyone in the team values it
Process
This might be surprising, but you need the processes in place to support building working software. How do you ensure that code is reviewed and tested before it goes into production? We use a structured process driven by Jira to ensure that every piece of work goes through all the steps that ensure quality.
We’ve adopted a Microservice strategy and one side effect of this is if you miss deploying a service, you could introduce problems. So you need a process to ensure that deployments pick up all of the changes. In our case we have a shared wiki page in a standard format for each deployment and a couple of 5-10 minute meetings to make sure we’ve picked up everything that needs to be deployed.
Conclusion
Uptime can be a really useful indicator of the overall health of not just your platform but also your processes for building and deploying code. At Bench we’re still aiming for 100% uptime even if we haven’t quite got there yet.
